

Firstly, we have 9K subscribers in 3+ weeks. Thanks for your support

Introduction
This will be a long post, but I hope also useful.
Like the Glossary I posted last week, there is no taxonomy for machine learning and deep learning algorithms.
Most ML/DL problems are classification problems, and a small subset of algorithms can be used to solve most of them (ex: SVM. Logistic regression or Xgboost). In that sense, a full taxonomy may be overkill. However, if you really want to understand something, you need to know to acquire knowledge of a repertoire of algorithms – to overcome the known unknowns problem.
In this post, rather than present a taxonomy, I present a range of taxonomy approaches for machine learning and deep learning algorithms. Some of these are mathematical. If you are just beginning data science, start from the non-mathematical approaches to taxonomy. Don’t be tempted to go for the maths approach. But if you have an aptitude for maths, you should consider the maths approach because it gives you a deeper understanding. Also, I am a bit biased because many in my network in Oxford, MIT, Cambridge, Technion, etc would also take a similar maths-based approach.
Finally, I suggest one specific approach to taxonomy which I like and find most complete. It is complex but it is free to download.
Taxonomy approaches
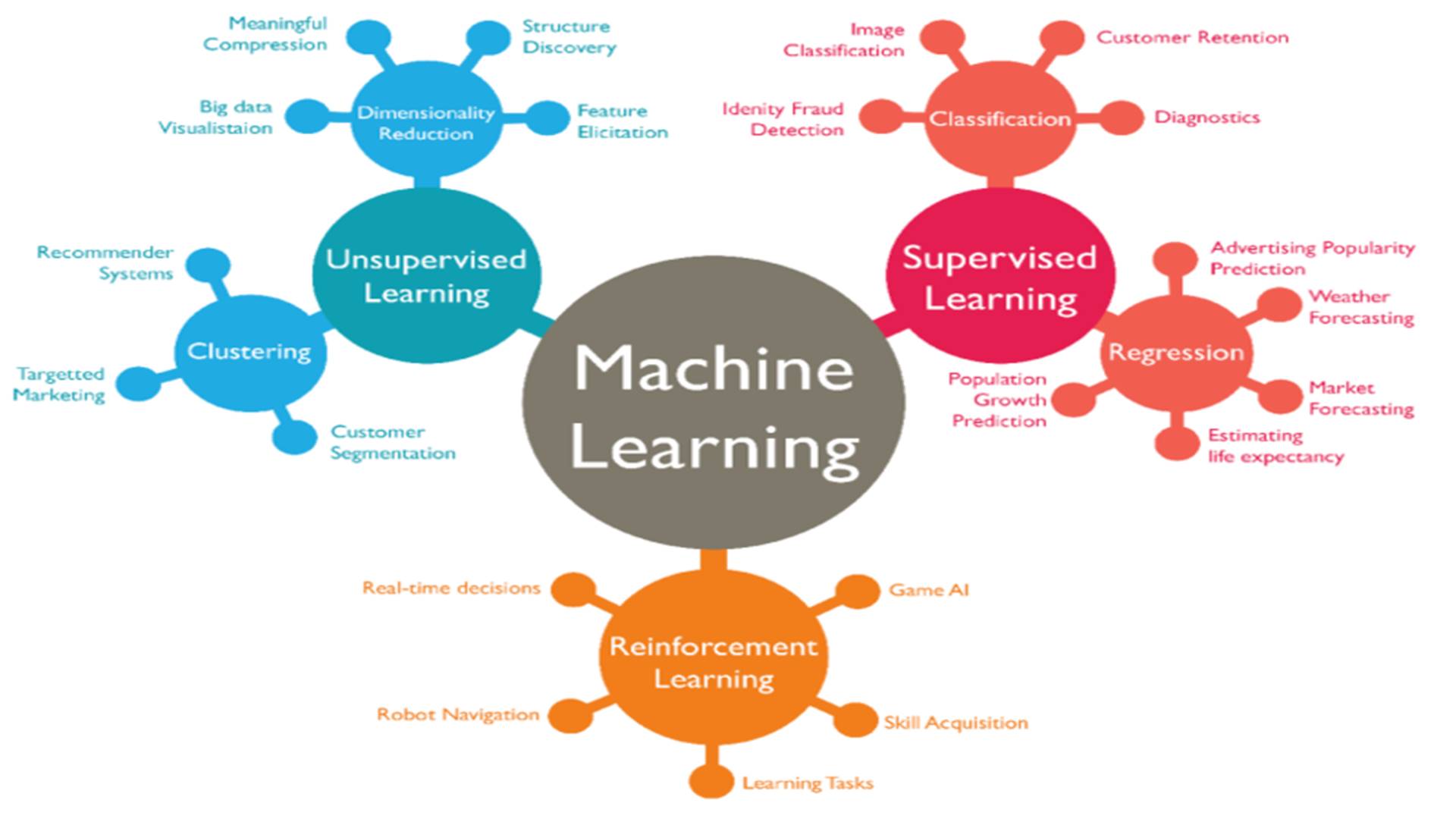
Firstly, the approach from Jason Brownlee is always a good place to start because it’s pragmatic and implementable in code in A tour of machine learning algorithms. Note that these are machine learning algorithms (not deep learning algorithms). A more visual approach is below source Packt.
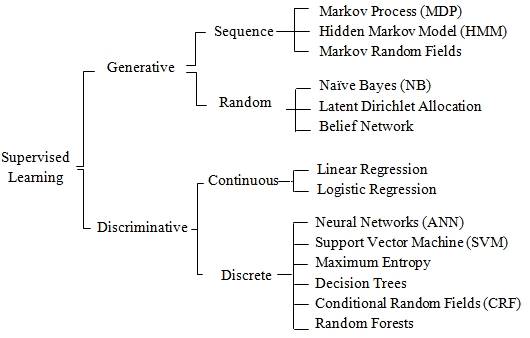

Another good taxonomy is by Peter Flach Machine Learning: The Art and Science of Algorithms a book which I like – and takes a specific approach. The basic idea for creating a taxonomy of algorithms is that we divide the instance space by using one of three ways:
· Using a Logical expression.
· Using the Geometry of the instance space.
· Using Probability to classify the instance space.
So, according to Flach, we have:
· logical models (tree-based and rule-based)
· geometric models (linear models, distance-based);
· probabilistic models (including generative models like GANs)
The book is not free but I blogged about it before. Since I like the approach. Note that the term instance space represents all possible input-output mappings and is related to two other terms – hypothesis space and sample space. Hypothesis space is all possible functions that map the x to y and sample space is a set of all possible outcomes
Digital transformation stalwart Bizagi hires the first CIO to reinforce organizational automation
Now, we jump up gears a bit. Pedro Domingos proposed in a talk at Google a ‘five approaches’ taxonomy. It is based on five paradigms: connectionist, evolutionary, Bayesian, analogy, and inductive logic programming(symbolist).


At this point, we get beyond the limitations of the current neural network-based paradigm (which is the connectionist model). To understand these issues, see the paper
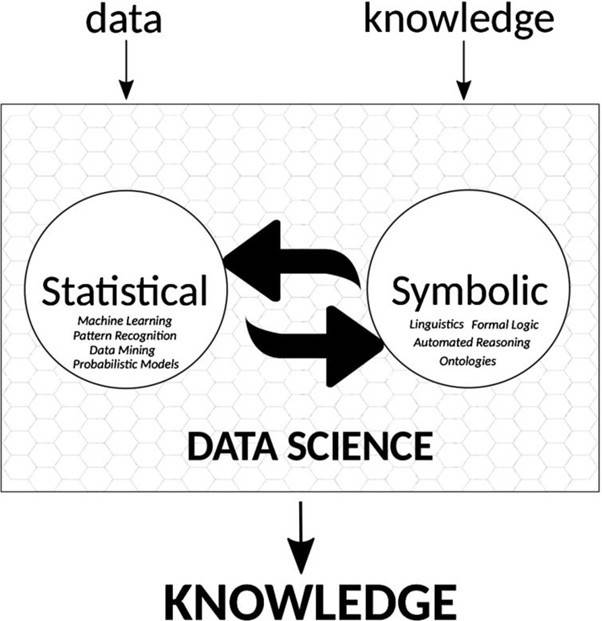
Data Science and symbolic AI: Synergies, challenges, and opportunities
The paper has a very nice diagram which I like

Finally, the approach I recommend is not a taxonomy rather a table of contents for an excellent book Machine Learning: A Probabilistic Perspective by Kevin Murphy. There is a 2012 version of the book but the latest (2022) version of the book is kindly free to download from MIT Press (as below). This concise version of the table of contents is from the 2022 version.
One important point is this book takes a Bayesian approach. The Bayesian versus frequentist approaches have long running differences of viewpoints. This has some implications for machine learning frequentist vs Bayesian approaches in machine learning
Hence, it’s based on Bayesian ideas like posterior probability but still considers frequentist concepts like p-value.
So, a version of the table of contents
Section One – Foundations
Probabilistic inference Introduction – Bayes’ rule – Bayesian concept learning- Bayesian machine learning
Probabilistic models Bernoulli and binomial distributions – Categorical and multinomial distributions – Univariate Gaussian (normal) distribution – Some other common univariate distributions – The multivariate Gaussian (normal) distribution – Linear Gaussian systems – Mixture models – Probabilistic graphical models
Parameter estimation Introduction – Maximum likelihood estimation (MLE) – Empirical risk minimization (ERM) – Regularization – The method of moments – Online (recursive) estimation – Parameter uncertainty
Optimization algorithms First-order methods – Second-order methods – Stochastic gradient descent – Constrained optimization – Proximal gradient method – Bound optimization – Blackbox and derivative free optimization
Information theory Entropy – Relative entropy (KL divergence) – Mutual information
Bayesian statistics Introduction – Conjugate priors – Noninformative priors – Hierarchical priors – Empirical priors – Bayesian model comparison – Approximate inference algorithms
Bayesian decision theory Bayesian decision theory – A/B testing – Bandit problems
Section Two: Linear models
Linear discriminant analysis Introduction – Gaussian discriminant analysis – Naive Bayes classifiers – Generative vs discriminative classifiers
Logistic regression Introduction – Binary logistic regression – Multinomial logistic regression – Preprocessing discrete input data – Robust logistic regression – Bayesian logistic regression
Linear regression Introduction – Standard linear regression – Ridge regression – Robust linear regression – Lasso regression – Bayesian linear regression
Generalized linear models Introduction – The exponential family – Generalized linear models (GLMs) – Probit regression
Section Three: Deep neural networks
Neural networks for unstructured data Introduction – Multilayer perceptrons (MLPs) – Backpropagation – Training neural networks – Regularization – Other kinds of feedforward networks
Neural networks for images Introduction – Basics – Image classification using CNNs – Solving other discriminative vision tasks with CNN’s – Generating images by inverting CNN’s – Adversarial Examples
Neural networks for sequences Introduction – Recurrent neural networks (RNNs) – 1d CNNs – Attention – Transformers – Efficient transformers
Section Four – Nonparametric models
Exemplar-based methods K nearest neighbor (KNN) classification – Learning distance metrics – Kernel density estimation (KDE)
Kernel methods Inferring functions from data – Mercer kernels – Gaussian processes – Scaling GPs to large datasets – Support vector machines (SVMs) – Sparse vector machines
Trees, forests, bagging and boosting Classification and regression trees (CART) – Ensemble learning – Bagging – Random forests – Boosting – Interpreting tree ensembles
Section Five: Beyond supervised learning
Learning with fewer labelled examples Data augmentation – Transfer learning – Meta-learning – Few-shot learning – Word embeddings – Semi-supervised learning – Active learning
Dimensionality reduction Principal components analysis (PCA) – Factor analysis – Autoencoders – Manifold learning
Clustering
Recommender systems
Graph embeddings
Book link is
https://probml.github.io/pml-book/book1.html
Reference
@book{pml1Book,
author = “Kevin P. Murphy”,
title = “Probabilistic Machine Learning: An introduction”,
publisher = “MIT Press”,
year = 2021,
url = “probml.ai“
}
Some jobs from my network
Pramod Bhandarkar recruiting for facebook reality labs
Todd Hester recruiting for Amazon robotics
Finally, some achievements from my students
Thomas Toseland gets a scholarship to a Quantum computing micrometers from Purdue
Rich Durham completes the Artificial Intelligence Cloud and Edge course
I also bought this amazing book – biography of Ronald McNair

