
Welcome to the third episode of my newsletter. In a week of launch, more than 7000 members have signed up for the newsletter
Many thanks for your support
Before we start, a bit of sad news from my side.
This week, I lost my father to COVID. I have shared a bit about my father.
Please stay safe
I will follow the same theme i.e. discuss a topic in AI followed by some job / funded research positions from my network and any Oxford courses which may be relevant.
In the last episode, I said that while AI is getting easier, there are many complex problems that need a more detailed analysis that spans beyond the traditional software engineering function.
One such example which I have used before is in the use of Generative Adversarial Networks (GANs) to augment data
Generative Adversarial Networks (GANs) are gaining a lot of traction in AI. On one hand, they can sound gimmicky i.e. to create fake videos and images. But the mathematical principles that underpin GANs can be very interesting and disruptive. In this post, we discuss how GANs can help in the creation of synthetic data.
The key principle is: A GAN when tuned, is capable of discerning the underlying distribution of a dataset.
The ability to understand an underlying distribution of a dataset is indeed a powerful idea because once a distribution is identified, it can be used to create copies of the same or similar objects. Thus, mathematically, the problem of generating fakes is actually a problem of density estimation.
To recap, a GAN is composed of two networks. The generator creates samples. The discriminator determines if they are real or not. The idea is to tune the two networks such that the generator can create ‘realistic fakes’. The generator and discriminator are trained together in an adversarial fashion until such time that the generator creates samples that can fool the discriminator. At which time, the generator is effectively mimicking the underlying distribution of the source data. Once tuned, you could in principle, discard the discriminator – and use the generator to create good fakes.
Mathematically, this idea can be shown to be equivalent to minimizing the Jensen-Shannon divergence between the true data density and the model data density. In probability theory and statistics, the Jensen–Shannon divergence is a method of measuring the similarity between two probability distributions.
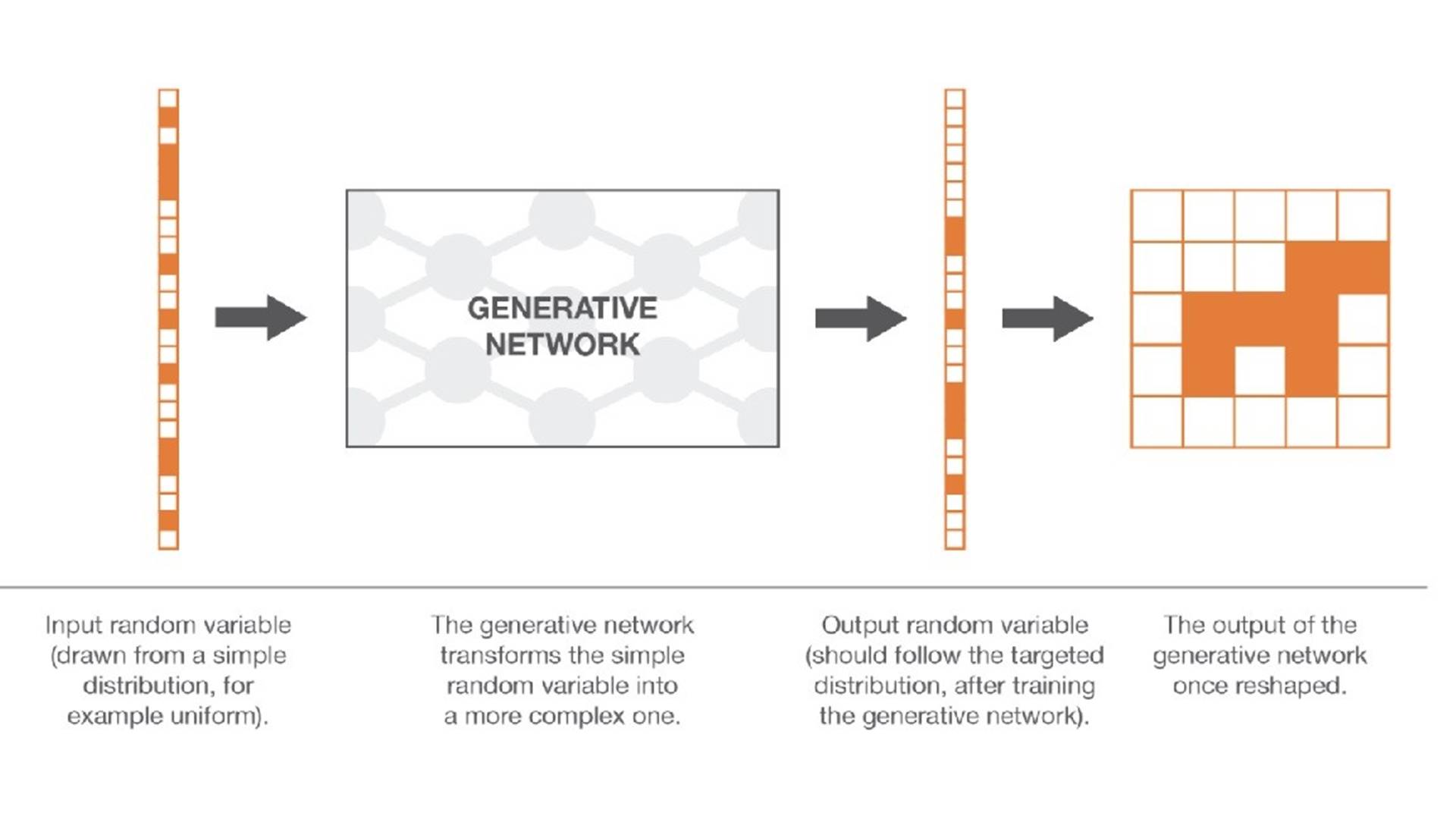
Now, we extend this idea to maths. The task of mimicking a distribution is similar to the task of generating pseudo-random sequences of numbers. Every image, for example, an image of a dog, can be treated as an n by n matrix. A matrix can be ‘flattened’ as a vector and can be fed to a neural network to detect an image of a dog. To generate a similar image, that of a dog, in this case, the GAN should be able to understand the underlying distribution in the N-dimensional vector space (comprising images of dogs)
In theory, there exists a probability distribution for other types of images (for cats, birds, etc) over an N-dimensional vector space. Thus, to generate an image of a specific type, we need to generate a new vector of a probability distribution of that type. This problem is similar to generating a pseudo-random number. We can extend this problem by learning a complex function from data capable of generating this N-dimensional random variable. The whole generator–discriminator mechanism then becomes a way to identify this unknown function that represents a distribution. The problem is opposite to a classification problem because instead of separating the two distributions, we try to bring them close to each other. This idea is shown in the image above. Image source Joseph Rocca
Cook vs. Zuckerberg: Apple and Facebook go to war over privacy
So, how do we use this concept to augment data?
In the paper Automated Augmentation with Reinforcement Learning and GANs for Robust Identification of Traffic Signs using Front Camera Images, the authors present an end-to-end framework to augment traffic sign training data using a GAN. From the original camera image, the augmenter enables learning from transformed images such as in nighttime, poor lighting, and varying degrees of occlusions. The pipeline is modified as shown below
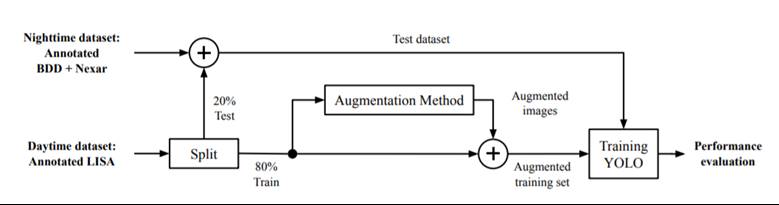
mage source: https://arxiv.org/pdf/1911.06486.pdf ·
Some final comments,
a) The exact nature and extent to which GANs manage to faithfully model the true data distribution in practice is still an open question
b) Mostly, this technique applies to continuous data. However, I found a good MIT link which talks of Generative Adversarial Nets with Reinforcement Learning for generating discrete data like text(as opposed to continuous data like images)
Trust you find the above analysis useful.
Jobs / funded Ph.D. positions and announcements
Our course is almost closed at #universityofOxford Developing Artificial Intelligence Applications
Also here are some interesting roles / funded Ph.D. positions from my network
Nuno Moniz funded Ph.D. position in Europe
Sam Wigglesworth Data ethics interns the UK
Umberto Picchini senior lecturer positions in maths and AI in Stockholm
Prof Subramanian Ramamoorthy AI Robotics fully funded Ph.D. position in the University of Edinburgh
Daniele Magazzeni AI/ ML roles at JP Morgan in London
Napomena o autorskim pravima: Dozvoljeno preuzimanje sadržaja isključivo uz navođenje linka prema stranici našeg portala sa koje je sadržaj preuzet. Stavovi izraženi u ovom tekstu autorovi su i ne odražavaju nužno uredničku politiku The Balkantimes Press.
Copyright Notice: It is allowed to download the content only by providing a link to the page of our portal from which the content was downloaded. The views expressed in this text are those of the authors and do not necessarily reflect the editorial policies of The Balkantimes Press.